【海云捷迅云课堂】高性能虚拟机NUMA
日期:2020-08-14
云课堂专题
海云捷迅云课堂专题,旨在秉承开源理念,为大家提供OpenStack技术原理与实践经验,该专题文章均由海云捷迅工程师理论与实践相结合总结而成,如大家有其他想要了解的信息,可留言给我们,我们会根据问题酌情回复。
NUMA 全称 Non-Uniform Memory Access,译为“非一致性内存访问”。该构架最大优势是可以把几十个CPU(甚至上百个CPU)组合在一个服务器内。方便更好的发挥系统性能。海云捷迅AWCloud3.1版本后,新增加了NUMA拓扑的高级选项,下文是对该架构的详解。
NUMA架构优势
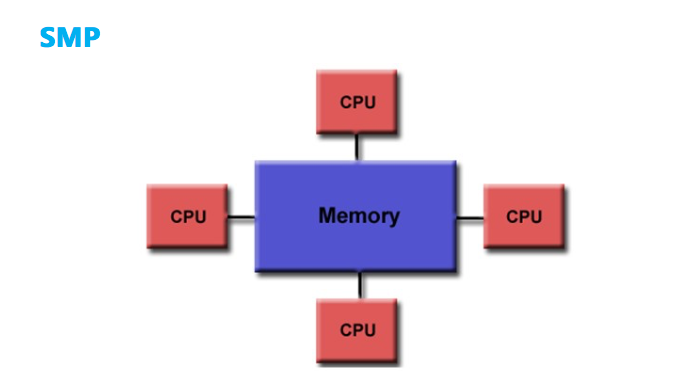
计算平台体系结构通常用的有SMP 对称多处理结构、NUMA 非统一内存访问结构、MPP 大规模并行处理结构三种结构。本文只对SMP和NUMA做简单的对比,MPP暂不放在对比的范围。先看下SMP的架构。
图片来源于网络
据上图所示可了解到计算机处理数据,需经磁盘-内存-cpu,对于SMP 这样的架构,集中式共享存储器的设计限制了处理器访问存储器的频次,导致处理器可能会经常处于对数据访问的饥饿状态。
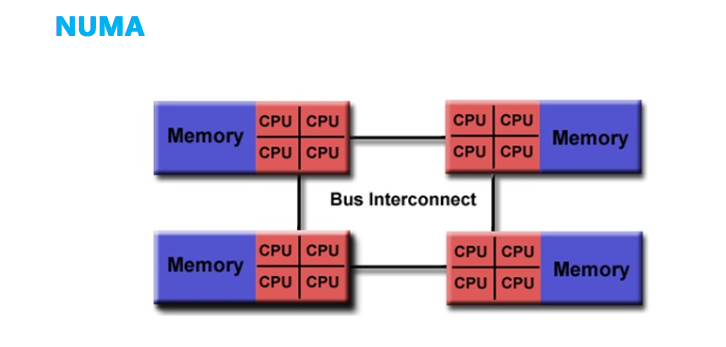
而对于NUMA的架构,它将处理器和存储器划分到不同的节点(NUMA Node),它们拥有几乎相等的资源。NUMA 节点内部会通过自己的存储总线访问内部的本地内存,而所有 NUMA 节点都可以通过主板上的共享总线来访问其他节点的远程内存。NUMA架构如下图所示
图片来源于网络
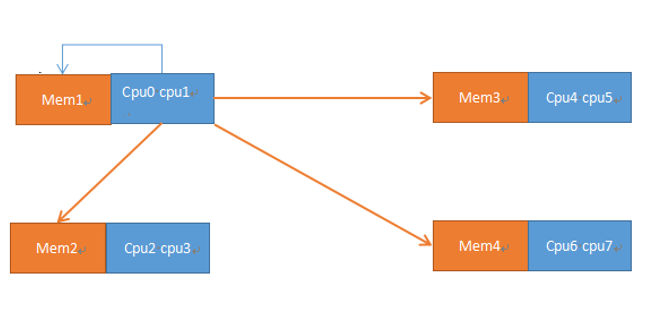
NUMA结构中有一个访问本地内存和访问远程内存的概念,访问本地内存既只访问NUMA节点内的内存,远程内存就是指访问其他NUMA节点的内存,如下图所示,CPU0和CPU1访问MEM1就是访问本地内存,访问的速度就会很快,访问MEM2-4就是远程内存,访问会变慢。
NUMA的结构设计能够在一定程度上解决 SMP 低存储带宽的问题。假如有一个2NUMA节点的系统,每一个节点内部具有 1GB/s 的存储带宽,外部共享总线也同样具有1GB/s 的带宽。理想状态下,如果所有的处理器总是访问本地内存的话,那么系统就拥有了 4GB/s 的存储带宽能力,在最不理想的情况下,如果所有处理器总是访问远程内存的话,那么系统就只能有 1GB/s 的存储带宽能力。
如果一个虚拟机的vCPU跨不同的Node的话,就会导致一个Node中的CPU去 访问另外一个Node中的内存的情况,这就导致内存访问延迟的增加。在有些特殊场景下,对虚拟机的性能有比较高的要求,就非常需要同一个虚拟机 的vCPU尽量被分配到同一个Node中的CPU上,所以在OpenStack的Kilo版本中增加了基于NUMA感知的虚拟机调度的特性。
如何查看物理机NUMA架构
首先需要了解与NUMA相关的几个概念有node、socket、core和thread。
Socket:主板上的CPU插槽
Core:一个物理CPU,一个独立的硬件执行单元
Thread:就是超线程hyperthread的概念,逻辑的执行单元
Node:Node是一个逻辑上的概念,对应于socket,NUMA使用node来管理CPU和内存,可以使用。
最常用的方法就是使用lscpu的命令直接查看物理机器的NUMA拓扑结构。
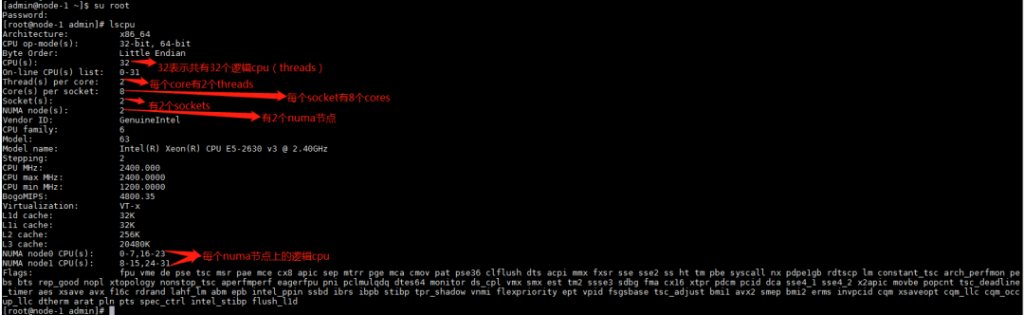
也可以分别查看使用ls /sys/devices/system/node/可以看到有几个NUMA节点,测试机器有node0和node1两个

Socket的信息可以通过/proc/cpuinfo查看,里面的physical id标识的就是socket号,测试机器有两个socket。

core的信息,core也是通过/proc/cpuinfo查看,其中和core相关的信息有:

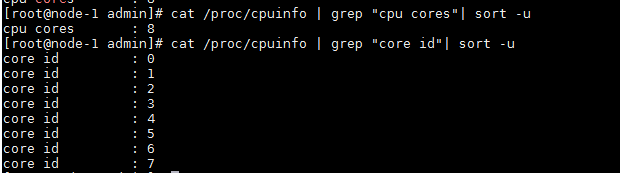
本次测试机每个socket有8个core Numa node的信息通过ls /sys/devices/system/node/node0直接查看,能看到每个节点对应的CPU和内存。
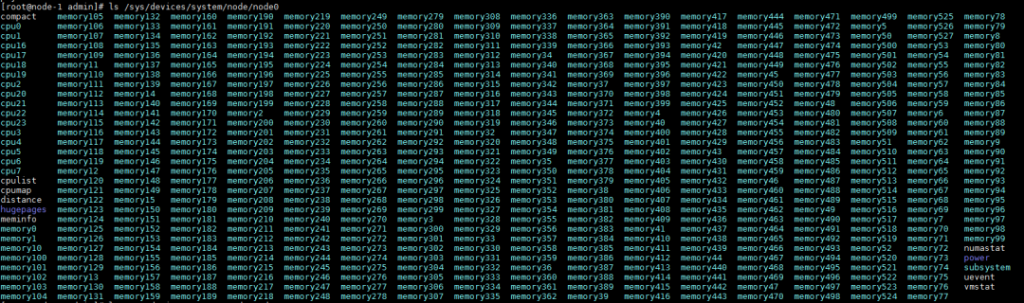
从上图可看到,cpu0-7以及cpu16-23属于同一个NUMA节点。
小扩展:这里还有L1 cache和L2 cache的概念,同一个NUMA节点上的CPU哪些可以共享同样的L1 Data Cache、L1 Instruction Cache、L2 Cache?感兴趣的可以自主了解
AWCloud虚拟机中的NUMA拓扑使用
基于NUMA的这种架构,对于一些高性能的虚拟机,需要同一个虚拟机的vCPU尽量被分配到同一个Node中的CPU上,在OpenStack的M版本中提供了接口。
主要体现在设置虚拟机的flavor和image这两个地方:
为Flavor添加元数据,即extra-specs,通过设置以下几种关键字入口:
hw:numa_nodes=NN – VM中NUMA的个数
hw:numa_mempolicy=preferred|strict – VM中 NUMA 内存的使用策略
hw:numa_cpus.0=<cpu-list> – VM 中在NUMA node 0的cpu
hw:numa_cpus.1=<cpu-list> – VM 中在NUMA node 1的cpu
hw:numa_mem.0=<ram-size> – VM 中在NUMA node 0的内存大小(M)
hw:numa_mem.1=<ram-size> – VM 中在NUMA node 1的内存大小(M)
为Image添加元数据,即Image的metadata,通过设置以下几种关键字:
hw_numa_nodes=NN – numa of NUMA nodes to expose to the guest.
hw_numa_mempolicy=strict|prefered – memory allocation policy
hw_numa_cpus.0=<cpu-list> – mapping of vCPUS N-M to NUMA node 0
hw_numa_cpus.1=<cpu-list> – mapping of vCPUS N-M to NUMA node 1
hw_numa_mem.0=<ram-size> – mapping N MB of RAM to NUMA node 0
hw_numa_mem.1=<ram-size> – mapping N MB of RAM to NUMA node 1
本次AWCloud的产品体现在Flavor上,下面举个例子说明
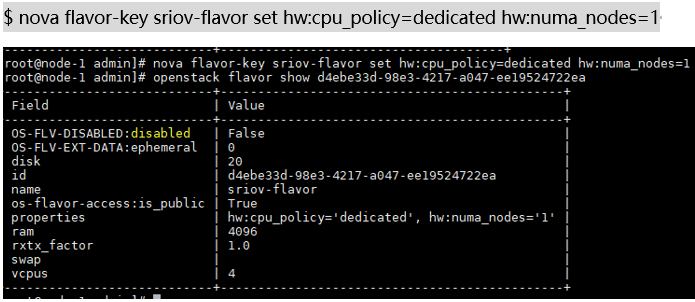
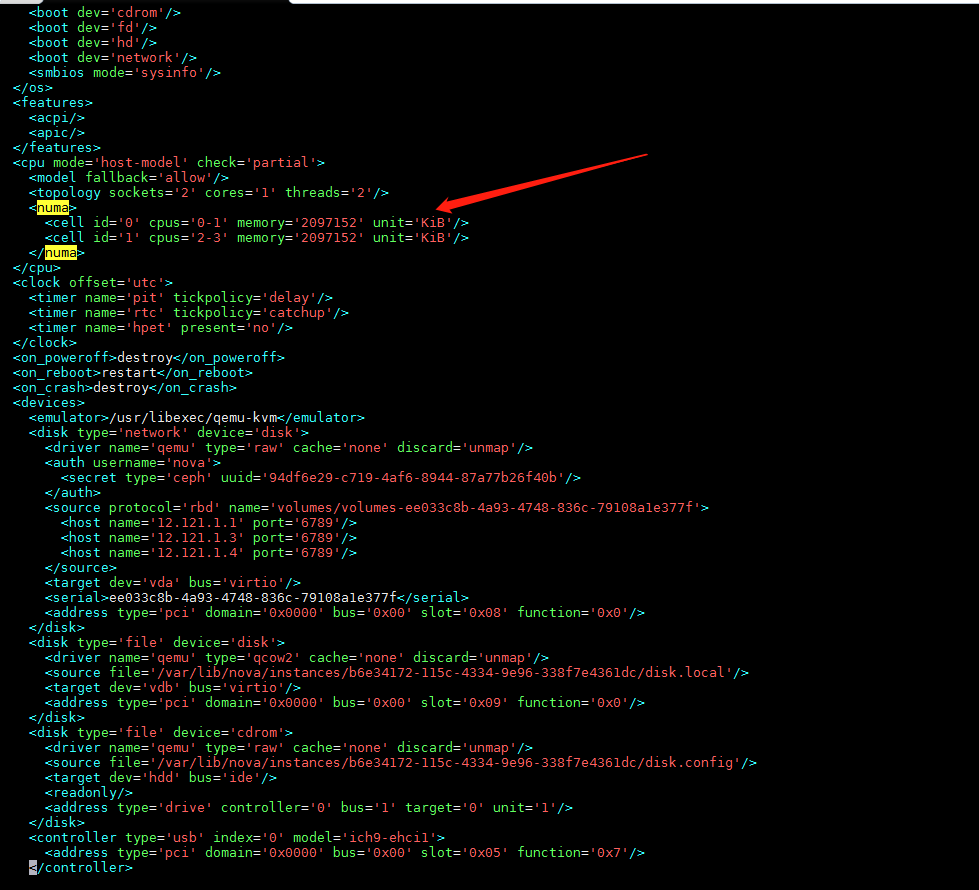
对于AWCloud产品,创建一个设置了NUMA拓扑的虚拟机只需要在创建普通虚拟机流程上,选择NUMA节点的个数、设置NUMA节点、设置NUMA策略即可。

下面展示的虚拟机配置了NUMA拓扑,我们可以在xml文件中看到NUMA的配置