
FPGA突破瓶颈,助力产业智能化 | 海云捷迅出席WAVE SUMMIT 2021 深度学习开发者峰会
日期:2021-05-21
新一代人工智能技术的发展,离不开深度学习框架这一基础。近几年,深度学习以前所未有的速度涌现,呈爆炸式发展,在人工智能领域不断取得突破。将深度学习技术赋能产业,是推进产业智能化进一步发展的核心动力。
5月20日,由深度学习技术及应用国家工程实验室与百度联合主办的WAVE SUMMIT 2021 深度学习开发者峰会在北京召开。会上百度首席技术官、深度学习技术及应用国家工程实验室主任王海峰以及百度技术专家,携手知名企业AI专家、高校学者、顶级开源项目发起人一起,共话AI产业应用、复合型AI人才培养、开源趋势。


海云捷迅依托自身在人工智能领域的不断创新,结合英特尔的先进技术和专业优势,致力于推动中国FPGA及人工智能生态建设快速发展,让AI赋能更多产业场景,加速AI应用落地。会上海云捷迅科技有限公司首席技术官田亮分享了以“FPGA赋能AI加速深度学习应用开发”为主题的演讲,详细介绍了FPGA在深度学习应用开发中的痛点及与Paddle对接的CNN加速器。


FPGA具有高性能、实时、灵活性特性,可实现高并行、低延迟、可定制、可编程的功能,因此在人工智能领域的应用越来越广泛。但FPGA深度学习开发面临着几大痛点:
- 开发难度大,算法导入困难,导致开发周期长,一个算法实现动辄数月;
- 软硬件结合难度大,软件工程师不懂FPGA硬件,FPGA工程师不懂软件;
- 缺少开发工具链做自动模型转换。
导致纵使FPGA对深度学习加速很有价值,也不敢轻易选择FPGA的技术路线。
那么如何解决这些痛点呢?我们必须选择一个主流的深度学习框架进行对接,从而加快人工智能算法在FPGA上的实现,扩展FPGA的应用场景,使开发难度不再成为技术推广的“拦路虎”。
我们选择了飞桨!因为好,所以用!原因为:
- 飞桨本身具备FPGA对接能力,可以加快英特尔FPGA的对接工作
- 飞桨技术支持反馈快
- 社区自身有良好的开发人员基础
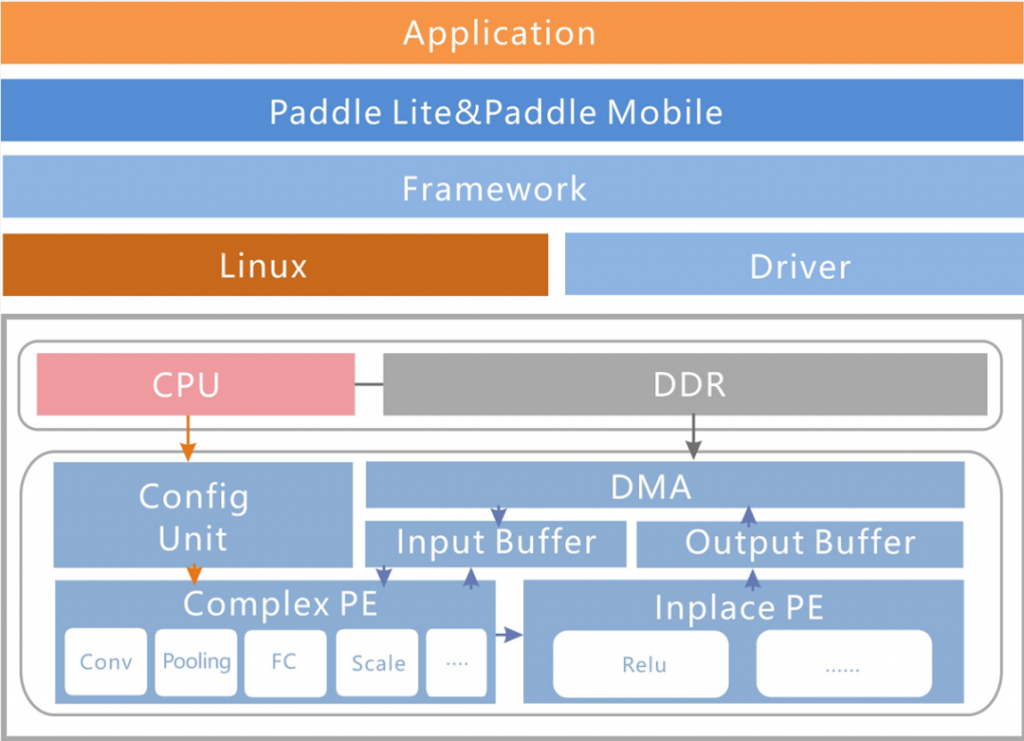
整体框架
- Intel FPGA的ARM侧部署Paddle Lite框架,结合海云自研的ARM侧的用户程序与驱动、FPGA 逻辑侧的算子,用户基于FPGA可以使用Paddle Lite框架对人工智能算法实现快速部署
- 相对于传统的在FPGA上部署人工智能算法,基于结合Paddle-Lite的Intel FPGA具有部署快,用户可以不关注底层硬件的特点
- 相对于在GPU、CPU上部署人工智能算法,基于结合Paddle-Lite的Intel FPGA具有低功耗、低延迟的特点,第一代发布版本的性能是FPGA内嵌硬核ARM的两倍,2.0发布版本性能是FPGA内嵌硬核ARM的7-10倍
与百度对接CNN加速器|人工智能边缘实验平台
- 易于硬件移植的金手指核心板形态,业内最小的CycloneV Soc核心板(6.7 x 5cm)
- 自主研发的人工智能边缘实验平台,将多个FPGA板卡放置在同一个服务器机箱中,为其提供电源接口、网络分配管理单元,形成FPGA资源池与paddle lite结合,提供丰富的案例
- 基于CycloneV Soc核心板结合丰富外设以及paddle lite框架,为工业边缘检测、安防、图像处理等提供算力



与百度对接CNN加速器|服务器端
- 基于Intel高端芯片 A10、S10加速卡结合paddle框架,主要应用于数据中心
- 提供一键部署与管理功能,为基因测序、金融加速、海量数据检测与处理等应用提供巨大算力与加速



此前,百度飞桨(PaddlePaddle)深度学习平台的高性能轻量化推理引擎Paddle Lite与海云捷迅自研的基于英特尔® FPGA开发套件正式完成兼容性适配。实现了人工智能算法的快速部署。
未来,海云捷迅将与Paddle Lite持续开展合作,更新后续版本,持续优化性能,不断兼容其他最新Intel芯片,Agilex系列。此外还将在RISC-V兼容Paddle框架上展开合作。除了在软硬件上充分结合,双方还将携手拓展更广泛的智能应用,推出行业标杆的解决方案,共同助力人工智能场景落地,赋予AI更多可能。




