
速度收藏!第六届集创赛海云捷迅杯得分要点总结?!
日期:2022-05-20
第六届集创赛已经开赛一个多月,
不知道同学们现在的进度如何呢?
海云捷迅杯第六届的赛题跟第五届相比明显更复杂了,
为了帮助同学们更好的完成比赛,
小编重新整理了同学们在比赛中会遇到的问题。
希望能给参赛的同学们带来一点思路,
以及能更好地解决同学们在参赛过程中遇到的难点。
#1 赛题要求
本次海云捷迅杯赛题的资源中提供了基于Intel FPGA CycloneV的CNN加速器。从下图可以看出本次赛题需要做的内容包括了SSD_MobileNetV1模型训练、模型优化(PaddleDetection);推理框架(Paddle-Lite);模型推理。
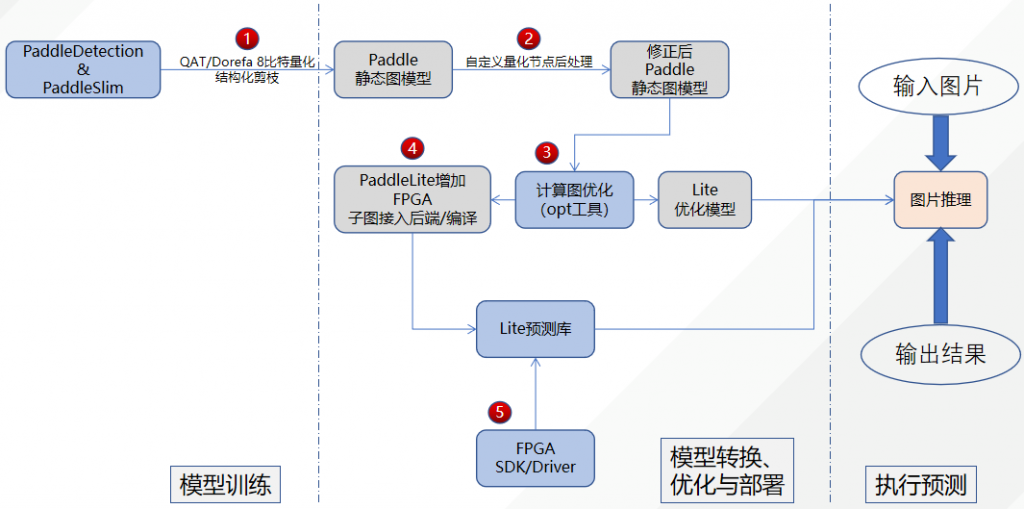
同样从上图中可以看到推荐的优化点包含了:
- 使用PaddleDetection组件训练ssd_mobilenet_v1,并调用PaddleSlim QAT量化接口进行8比特量化,也可以将激活值和权重量化节点替换成自定义量化节点,如dorefa 8比特量化。
- 在导出静态图模型时,需要处理自定义量化节点,以便于在Paddle-Lite部署。
- Opt工具负责计算图进行优化,期间包含对量化节点的处理,如对添加Dorefa 8比特量化算法的支持。
- 因为Paddle-Lite以子图接入的方式接入FPGA后端,所以需要添加子图检测的PASS去检测调度到FPGA执行的算子。在构建硬件图IR的过程中,进行权重重排。
- Paddle-Lite在推理时采用ARM+FPGA的混合调度策略,由FPGA卷积和DW卷积算子构成的子图通过FPGA运行时接口调度到FPGA执行,其他算子在ARM执行。
我们将计算量大的卷积算子全部量化为8bit定点,这样可以在FPGA的PL端使用加速器来进行卷积运算,起到加速的效果。减少ARM和FPGA之间的频繁交互,大大缩短推理的时间。这里我们使用的是PaddleDetection加上PaddleSlim进行了QAT 8bit量化。这一步我们使用Paddle-Lite和PaddleSlim的默认配置脚本就能完成。
如果想要在模型训练这一点上进行更多的优化,可以利用PaddleSlim进行进一步的剪枝训练。当然也可以使用其它框架进行训练和模型优化,然后再使用Paddle工具进行模型转换。
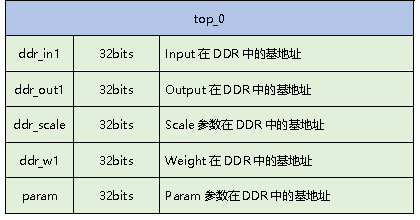
如果要使用海云捷迅提供的CNN加速器,首先第一步需要编写CNN加速器的驱动,在实际比赛过程中提供了CNN加速器驱动的实例nnadrv,参赛团队可以在nnadrv的基础之上进行修改、优化;接着需要修改Paddle-Lite进行加速器适配。
在加速器适配过程中,我们需要完成针对Intel FPGA CNN加速器的子图注册,以保证8bit卷积能顺利调度到nnadrv驱动。同时,为了保证CNN加速器能顺利的完成计算并返回正确的结果,我们需要在调度nnadrv之前对数据进行重排以适配nnadrv的接口。这一部分在Intel_fpga_sdk中完成,可以参考Demo中提供的intel_fpga_sdk文件夹。
注意:如果是自己调用make函数或者自己编写编译脚本,请观察赛事提供的Demo包中的intel_fpga_sdk文件夹中的build.sh中的第16/17行,编译完成以后有一个将编译好的libifcnna.so文件拷贝到上一级目录../libvnna.so的操作。

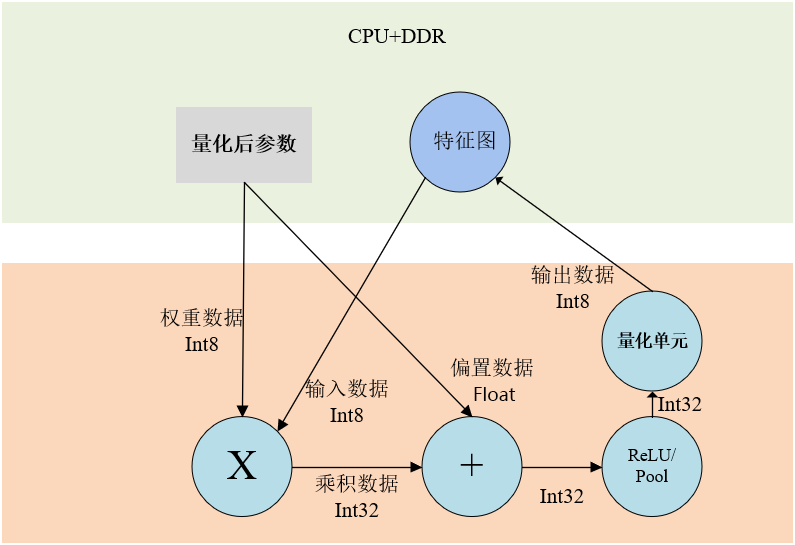
- 首先特征图和权重参数都量化为8bit定点,为了保持精度,激活参数还是保留float32
- 计算完成以后通过PL端的量化单元操作变为8bit定点存入PS的DDR
- 如果下一次的操作PL端的加速器还是支持,比如是DW卷积或者3X3和1X1的普通卷积,则直接从PS端的DDR取数据,开始下一次的操作,这样可以不用ARM介入,大大加快了推理时间
- 如果本次的卷积操作以后,下一次的操作PL端的加速器不支持,则自动调用ARM处理器来完成操作



#2 Demo
| |__include Paddle-Lite编译所得头文件
| |__lib
| |__libifcnna.so intel_fpga_sdk编译的库文件
| |__libappdle_* Paddle-Lite编译所得库文件
|__config_ssd_mobilenet_v1.cfg demo配置脚本,配置了所需文件路径、图片预处理参数等等
|__images 需要推理的图片,在run.sh中进行指定
|__labels label列表文件,在config_ssd_mobilenet_v1.cfg中指定
|__lib 依赖库存放文件夹
|__nnadrv.ko 加速器驱动,由nnadrv.ko文件编译所得
|__run.sh demo启动脚本文件
|__ocv3.4.10 OpenCV库文件夹
|__ssd_detection_src demo源码文件夹
|__ssd_mobilenet_v1 模型存放文件夹
注:Ssd_detection_demo的入口文件在ssd_detection_src/ssd_detection.cc中的main函数。
#3 作品提交流程
1 汇报PPT:项目介绍、关键技术介绍、性能指标
b.关键技术介绍:技术创新点介绍、后续工作
c. 性能指标:目前已达到性能水平(推理速度)
b.关键技术分析:对作品使用到的关键技术进行深入分析、讲解
c.性能分析:从模块到集成,详细分析框架的性能特性及优势点,并进行佐证
b.仿真及测试报告:结合图表、数据、波形图、打印信息等各种手段对作品进行仿真和测试,并出具详细报告。
更多注意事项及答疑内容
详见海云捷迅官网集创赛专区
PC端地址:https://www.awcloud.com/FAQ/4.html




